
@inproceedings{NEURIPS2024_aaa0ac42,
author = {Keren Taraday, Mitchell and David, Almog and Baskin, Chaim},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Globerson and L. Mackey and D. Belgrave and A. Fan and U. Paquet and J. Tomczak and C. Zhang},
pages = {93985--94021},
publisher = {Curran Associates, Inc.},
title = {Sequential Signal Mixing Aggregation for Message Passing Graph Neural Networks},
url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/aaa0ac4253da75faf9b0dc0dda062612-Paper-Conference.pdf},
volume = {37},
year = {2024}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.

@article{0cfceec4b0ac487fa3b97d82b37d9a92,
title = "Frontiers in Flexible and Shape-Changing Arrays",
abstract = "Shape-changing arrays are an emerging frontier of phased array development. These arrays fold, conform, and flex dynamically as they operate. In this work we describe the technology developments which have enabled their creation and use. We present the theoretical implications of aperture change for arrays and methods for taking advantage of these aperture changes. We discuss existing shape-changing array components and systems. Operation techniques for shape-changing arrays, including new results demonstrating a method for determining the shape of an asymmetrically bent flexible array using only the mutual coupling between elements, are shown. Finally, we present a comparison of shape-changing systems across a variety of physical and electrical metrics.",
keywords = "MTT 70th Anniversary Special Issue, deployable, flexible electronics, flexible phased array, integrated circuit based array, origami, shape-changing array, stretchable electronics",
author = "Fikes, \{Austin C.\} and Matan Gal-Katziri and Mizrahi, \{Oren S.\} and Williams, \{D. Elliott\} and Ali Hajimiri",
note = "Publisher Copyright: {\textcopyright} 2021 IEEE.",
year = "2023",
month = jan,
day = "1",
doi = "10.1109/JMW.2022.3226125",
language = "American English",
volume = "3",
pages = "349--367",
journal = "IEEE Journal of Microwaves",
issn = "2692-8388",
publisher = "Institute of Electrical and Electronics Engineers Inc.",
number = "1",
}copy to clipboardShape-changing arrays are an emerging frontier of phased array development. These arrays fold, conform, and flex dynamically as they operate. In this work we describe the technology developments which have enabled their creation and use. We present the theoretical implications of aperture change for arrays and methods for taking advantage of these aperture changes. We discuss existing shape-changing array components and systems. Operation techniques for shape-changing arrays, including new results demonstrating a method for determining the shape of an asymmetrically bent flexible array using only the mutual coupling between elements, are shown. Finally, we present a comparison of shape-changing systems across a variety of physical and electrical metrics.
Deep neural networks are known to be vulnerable to malicious perturbations. Current methods for improving adversarial robustness make use of either implicit or explicit regularization, with the latter is usually based on adversarial training. Randomized smoothing, the averaging of the classifier outputs over a random distribution centered in the sample, has been shown to guarantee a classifier’s performance subject to bounded perturbations of the input. In this work, we study the application of randomized smoothing to improve performance on unperturbed data and increase robustness to adversarial attacks. We propose to combine smoothing along with adversarial training and randomization approaches, and find that doing so significantly improves the resilience compared to the baseline. We examine our method’s performance on common white-box (FGSM, PGD) and black-box (transferable attack and NAttack) attacks on CIFAR-10 and CIFAR-100, and determine that for a low number of iterations, smoothing provides a significant performance boost that persists even for perturbations with a high attack norm, 𝜖.
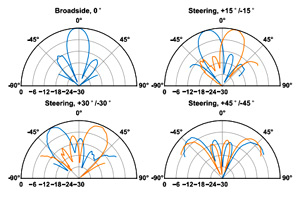
@ARTICLE{9684945,
author={Gal-Katziri, Matan and Ives, Craig and Khakpour, Armina and Hajimiri, Ali},
journal={IEEE Journal of Solid-State Circuits},
title={Optically Synchronized Phased Arrays in CMOS},
year={2022},
volume={57},
number={6},
pages={1578-1593},
keywords={Clocks;Optical transmitters;Phased arrays;Synchronization;Optical arrays;Optical receivers;Radio frequency;CMOS;injection-locked oscillators (ILOs);optoelectronics;phased arrays;photodiodes (PDs);silicon photonics},
doi={10.1109/JSSC.2021.3136787}}
copy to clipboardOptical synchronization of large-span arrays offers significant benefits over electrical methods in terms of the weight, cost, power dissipation, and complexity of the clock distribution network. This work presents the analysis and design of the first phased array transmitter synchronized using a fully monolithic CMOS optical receiver. We demonstrate a bulk CMOS, 8-element, 28-GHz phased array building block with an on-chip photodiode (PD) that receives and processes the optical clock and uses an integrated PLL to generate eight independent phase-programmable RF outputs. The system demonstrates beam steering, data transmission, and remote synchronization of array elements at 28 GHz with fiber lengths up to 25 m, in order to show the scaling benefits of our approach. The provision of small footprint and cost-effective CMOS transceivers with integrated optoelectronic receivers enables exciting opportunities for low-cost and ultralight array systems.
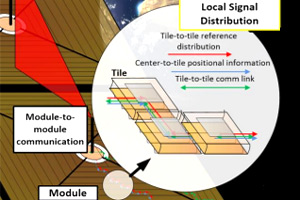
@inproceedings{Abiri2022ALS,
title={A Lightweight Space-based Solar Power Generation and Transmission Satellite},
author={Behrooz Abiri and Manan Arya and Florian Bohn and Austin C. Fikes and Matan Gal-Katziri and Eleftherios Gdoutos and Ashish Goel and Pilar Espinet Gonz{\'a}lez and Michael D. Kelzenberg and Nicolas Lee and Michael A. Marshall and Tatiana A. Roy and Fabien Royer and Emily C. Warmann and Tatiana G. Vinogradova and Richard G. Madonna and Harry A. Atwater and Ali Hajimiri and S{\'e}rgio Roberto Matiello Pellegrino},
year={2022},
url={https://api.semanticscholar.org/CorpusID:249848189}
}copy to clipboardWe propose a novel design for a lightweight, high-performance space-based solar power array combined with power beaming capability for operation in geosynchronous orbit and transmission of power to Earth. We use a modular configuration of small, repeatable unit cells, called tiles, that each individually perform power collection, conversion, and transmission. Sunlight is collected via lightweight parabolic concentrators and converted to DC electric power with high efficiency III-V photovoltaics. Several CMOS integrated circuits within each tile generates and controls the phase of multiple independently-controlled microwave sources using the DC power. These sources are coupled to multiple radiating antennas which act as elements of a large phased array to beam the RF power to Earth. The power is sent to Earth at a frequency chosen in the range of 1-10 GHz and collected with ground-based rectennas at a local intensity no larger than ambient sunlight. We achieve significantly reduced mass compared to previous designs by taking advantage of solar concentration, current CMOS integrated circuit technology, and ultralight structural elements. Of note, the resulting satellite has no movable parts once it is fully deployed and all beam steering is done electronically. Our design is safe, scalable, and able to be deployed and tested with progressively larger configurations starting with a single unit cell that could fit on a cube satellite. The design reported on here has an areal mass density of 160 g/m2 and an end-to-end efficiency of 7-14%. We believe this is a significant step forward to the realization of space-based solar power, a concept once of science fiction.
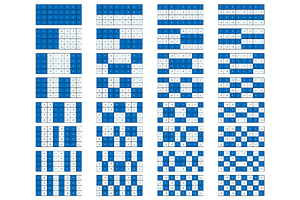
@ARTICLE{9270598,
author={Hajimiri, Ali and Abiri, Behrooz and Bohn, Florian and Gal-Katziri, Matan and Manohara, Mohith H.},
journal={IEEE Journal of Solid-State Circuits},
title={Dynamic Focusing of Large Arrays for Wireless Power Transfer and Beyond},
year={2021},
volume={56},
number={7},
pages={2077-2101},
keywords={Radio frequency;Phased arrays;Wireless power transfer;Focusing;Finite element analysis;Apertures;Antenna arrays;Calibration;dynamic refocusing;orthogonal basis;phased array;power focusing;pseudo-Hadamard matrices;pseudo-orthogonal bases;RF lensing;wireless power transfer at a distance (WPT-AD);wireless power transfer},
doi={10.1109/JSSC.2020.3036895}}copy to clipboardWe present architectures, circuits, and algorithms for dynamic 3-D lensing and focusing of electromagnetic power in radiative near- and far-field regions by arrays that can be arbitrary and nonuniform. They can benefit applications such as wireless power transfer at a distance (WPT-AD), volumetric sensing and imaging, high-throughput communications, and optical phased arrays. Theoretical limits on system performance are calculated. An adaptive algorithm focuses the power at the receiver(s) without prior knowledge of its location(s). It uses orthogonal bases to change the phases of multiple elements simultaneously to enhance the dynamic range. One class of such 2-D orthogonal and pseudo-orthogonal masks is constructed using the Hadamard and pseudo-Hadamard matrices. Generation and recovery units (GU and RU) work collaboratively to focus energy quickly and reliably with no need for factory calibration. Orthogonality enables batch processing in high-latency and low-rate communication settings. Secondary vector-based calculations allow instantaneous refocusing at different locations using element-wise calculations. An emulator enables further evaluation of the system. We demonstrate modular WPT-AD GUs of up to 400 elements utilizing arrays of 65-nm CMOS ICs to focus power on RUs that convert the RF power to dc. Each RFIC synthesizes 16 independently phase-controlled RF outputs around 10 GHz from a common single low-frequency reference. Detailed measurements demonstrate the feasibility and effectiveness of RF lensing techniques presented in this article. More than 2 W of dc power can be recovered through a wireless transfer at distances greater than 1 m. The system can dynamically project power at various angles and at distances greater than 10 m. These developments are another step toward unified wireless power, sensing, and communication solutions in the future.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Moshe Guy and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@article{
kimhi2024semisupervised,
title={Semi-Supervised Semantic Segmentation via Marginal Contextual Information},
author={Moshe Kimhi and Shai Kimhi and Evgenii Zheltonozhskii and Or Litany and Moshe Guy},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=i5yKW1pmjW},
note={}
}copy to clipboardWe present a novel confidence refinement scheme that enhances pseudo-labels in semi-supervised semantic segmentation. Unlike existing methods, which filter pixels with low-confidence predictions in isolation, our approach leverages the spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo-labels collectively. With this contextual information, our method, named S4MC, increases the amount of unlabeled data used during training while maintaining the quality of the pseudo-labels, all with negligible computational overhead. Through extensive experiments on standard benchmarks, we demonstrate that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution for reducing the cost of acquiring dense annotations. For example, S4MC achieves a 1.39 mIoU improvement over the prior art on PASCAL VOC 12 with 366 annotated images.
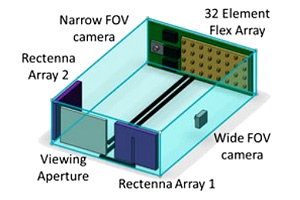
We provide an update on the Caltech Space Solar Power Project (SSPP). Our space power station employs a “sandwich” architecture where solar energy is collected on one side of a plate and coherent RF is transmitted out the other, eliminating the need for transport of large DC currents across the power station. Lightweight custom ICs synthesize, synchronize, and amplify RF signals to convert the DC power, and provide synchronous control of all RF sources to form a transmission phase array enabling wireless power transmission at a distance. We use highly flexible photovoltaics (PV), substrates for printed circuit boards, and either patch or pop-up antennas supported by a foldable and rollable carbon fiber structure to package a large (nominally 60m x 60m) multilayered structure into a relatively small cylindrical volume. In order to increase overall efficiency, we employ radio frequency (RF) transparent PV over the antenna layer on one side of the sandwich and PV on the other to allow the antennas to point at the earth almost continually while in a geosynchronous equatorial orbit. We also have explored using optically transparent antennas over the PV layer which opens options for the types of antennas we can use. We summarize our progress to date and briefly discuss our impending on-orbit demonstration payload.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.
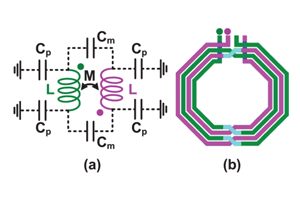
This paper presents the analysis and design of a novel magnetic sensor. We study the underlying physics of inductance shift sensors as a special case of the broader family of magnetic energy deviation sensors. The result is a quantitative definition of performance metrics with all assumptions and approximations explicitly stated. This analysis is then used to design a modified ac Wheatstone bridge that uses two inductorpairs in a cross-coupled configuration, to half its size and double its transducer gain while maintaining a fully differential structure with a matched frequency response. A proof-of-concept sensor was fabricated with peripheral circuitry in a 65-nm bulk CMOS process to operate between 770 and 1450 MHz with an effective sensing area of 200 μm × 200 μm. The new bridge sensor is fully characterized at a frequency of 770 MHz and demonstrates a reliable and continuous detection of 4.5-μm iron-oxide magnetic beads over time periods longer than 30 min, appreciably longer than previously reported works.
Graph neural networks (GNNs) have shown broad applicability in a variety of domains. These domains, e.g., social networks and product recommendations, are fertile ground for malicious users and behavior. In this paper, we show that GNNs are vulnerable to the extremely limited (and thus quite realistic) scenarios of a single-node adversarial attack, where the perturbed node cannot be chosen by the attacker. That is, an attacker can force the GNN to classify any target node to a chosen label, by only slightly perturbing the features or the neighbors list of another single arbitrary node in the graph, even when not being able to select that specific attacker node. When the adversary is allowed to select the attacker node, these attacks are even more effective. We demonstrate empirically that our attack is effective across various common GNN types (e.g., GCN, GraphSAGE, GAT, GIN) and robustly optimized GNNs (e.g., Robust GCN, SM GCN, GAL, LAT-GCN), outperforming previous attacks across different real-world datasets both in a targeted and non-targeted attacks.
Graph neural networks (GNNs) have shown broad applicability in a variety of domains. These domains, e.g., social networks and product recommendations, are fertile ground for malicious users and behavior. In this paper, we show that GNNs are vulnerable to the extremely limited (and thus quite realistic) scenarios of a single-node adversarial attack, where the perturbed node cannot be chosen by the attacker. That is, an attacker can force the GNN to classify any target node to a chosen label, by only slightly perturbing the features or the neighbors list of another single arbitrary node in the graph, even when not being able to select that specific attacker node. When the adversary is allowed to select the attacker node, these attacks are even more effective. We demonstrate empirically that our attack is effective across various common GNN types (e.g., GCN, GraphSAGE, GAT, GIN) and robustly optimized GNNs (e.g., Robust GCN, SM GCN, GAL, LAT-GCN), outperforming previous attacks across different real-world datasets both in a targeted and non-targeted attacks.
@article{
kimhi2024semisupervised,
title={Semi-Supervised Semantic Segmentation via Marginal Contextual Information},
author={Moshe Kimhi and Shai Kimhi and Evgenii Zheltonozhskii and Or Litany},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=i5yKW1pmjW},
note={}
}copy to clipboardWe present a novel confidence refinement scheme that enhances pseudo-labels in semi-supervised semantic segmentation. Unlike existing methods, which filter pixels with low-confidence predictions in isolation, our approach leverages the spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo-labels collectively. With this contextual information, our method, named S4MC, increases the amount of unlabeled data used during training while maintaining the quality of the pseudo-labels, all with negligible computational overhead. Through extensive experiments on standard benchmarks, we demonstrate that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution for reducing the cost of acquiring dense annotations. For example, S4MC achieves a 1.39 mIoU improvement over the prior art on PASCAL VOC 12 with 366 annotated images.
Graph neural networks (GNNs) have shown broad applicability in a variety of domains. These domains, e.g., social networks and product recommendations, are fertile ground for malicious users and behavior. In this paper, we show that GNNs are vulnerable to the extremely limited (and thus quite realistic) scenarios of a single-node adversarial attack, where the perturbed node cannot be chosen by the attacker. That is, an attacker can force the GNN to classify any target node to a chosen label, by only slightly perturbing the features or the neighbors list of another single arbitrary node in the graph, even when not being able to select that specific attacker node. When the adversary is allowed to select the attacker node, these attacks are even more effective. We demonstrate empirically that our attack is effective across various common GNN types (e.g., GCN, GraphSAGE, GAT, GIN) and robustly optimized GNNs (e.g., Robust GCN, SM GCN, GAL, LAT-GCN), outperforming previous attacks across different real-world datasets both in a targeted and non-targeted attacks.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Moshe Guy and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
Deep neural networks are known to be vulnerable to malicious perturbations. Current methods for improving adversarial robustness make use of either implicit or explicit regularization, with the latter is usually based on adversarial training. Randomized smoothing, the averaging of the classifier outputs over a random distribution centered in the sample, has been shown to guarantee a classifier’s performance subject to bounded perturbations of the input. In this work, we study the application of randomized smoothing to improve performance on unperturbed data and increase robustness to adversarial attacks. We propose to combine smoothing along with adversarial training and randomization approaches, and find that doing so significantly improves the resilience compared to the baseline. We examine our method’s performance on common white-box (FGSM, PGD) and black-box (transferable attack and NAttack) attacks on CIFAR-10 and CIFAR-100, and determine that for a low number of iterations, smoothing provides a significant performance boost that persists even for perturbations with a high attack norm, 𝜖.
@ARTICLE{9270598,
author={Hajimiri, Ali and Abiri, Behrooz and Bohn, Florian and Gal-Katziri, Matan and Manohara, Mohith H.},
journal={IEEE Journal of Solid-State Circuits},
title={Dynamic Focusing of Large Arrays for Wireless Power Transfer and Beyond},
year={2021},
volume={56},
number={7},
pages={2077-2101},
keywords={Radio frequency;Phased arrays;Wireless power transfer;Focusing;Finite element analysis;Apertures;Antenna arrays;Calibration;dynamic refocusing;orthogonal basis;phased array;power focusing;pseudo-Hadamard matrices;pseudo-orthogonal bases;RF lensing;wireless power transfer at a distance (WPT-AD);wireless power transfer},
doi={10.1109/JSSC.2020.3036895}}copy to clipboardWe present architectures, circuits, and algorithms for dynamic 3-D lensing and focusing of electromagnetic power in radiative near- and far-field regions by arrays that can be arbitrary and nonuniform. They can benefit applications such as wireless power transfer at a distance (WPT-AD), volumetric sensing and imaging, high-throughput communications, and optical phased arrays. Theoretical limits on system performance are calculated. An adaptive algorithm focuses the power at the receiver(s) without prior knowledge of its location(s). It uses orthogonal bases to change the phases of multiple elements simultaneously to enhance the dynamic range. One class of such 2-D orthogonal and pseudo-orthogonal masks is constructed using the Hadamard and pseudo-Hadamard matrices. Generation and recovery units (GU and RU) work collaboratively to focus energy quickly and reliably with no need for factory calibration. Orthogonality enables batch processing in high-latency and low-rate communication settings. Secondary vector-based calculations allow instantaneous refocusing at different locations using element-wise calculations. An emulator enables further evaluation of the system. We demonstrate modular WPT-AD GUs of up to 400 elements utilizing arrays of 65-nm CMOS ICs to focus power on RUs that convert the RF power to dc. Each RFIC synthesizes 16 independently phase-controlled RF outputs around 10 GHz from a common single low-frequency reference. Detailed measurements demonstrate the feasibility and effectiveness of RF lensing techniques presented in this article. More than 2 W of dc power can be recovered through a wireless transfer at distances greater than 1 m. The system can dynamically project power at various angles and at distances greater than 10 m. These developments are another step toward unified wireless power, sensing, and communication solutions in the future.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Moshe Guy and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Moshe Guy and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@INPROCEEDINGS{Zlotnick2023covert,
author={Zlotnick, Elyakim and Bash, Boulat},
booktitle={Accepted for publication in IEEE Transactions on Information Theory},
title={Entanglement-Assisted Covert Communication via Qubit Depolarizing Channels},
year={2025},
volume={},
number={},
pages={},
keywords={},
doi={}}copy to clipboardDeep neural networks are known to be vulnerable to malicious perturbations. Current methods for improving adversarial robustness make use of either implicit or explicit regularization, with the latter is usually based on adversarial training. Randomized smoothing, the averaging of the classifier outputs over a random distribution centered in the sample, has been shown to guarantee a classifier’s performance subject to bounded perturbations of the input. In this work, we study the application of randomized smoothing to improve performance on unperturbed data and increase robustness to adversarial attacks. We propose to combine smoothing along with adversarial training and randomization approaches, and find that doing so significantly improves the resilience compared to the baseline. We examine our method’s performance on common white-box (FGSM, PGD) and black-box (transferable attack and NAttack) attacks on CIFAR-10 and CIFAR-100, and determine that for a low number of iterations, smoothing provides a significant performance boost that persists even for perturbations with a high attack norm, 𝜖.
We provide an update on the Caltech Space Solar Power Project (SSPP). Our space power station employs a “sandwich” architecture where solar energy is collected on one side of a plate and coherent RF is transmitted out the other, eliminating the need for transport of large DC currents across the power station. Lightweight custom ICs synthesize, synchronize, and amplify RF signals to convert the DC power, and provide synchronous control of all RF sources to form a transmission phase array enabling wireless power transmission at a distance. We use highly flexible photovoltaics (PV), substrates for printed circuit boards, and either patch or pop-up antennas supported by a foldable and rollable carbon fiber structure to package a large (nominally 60m x 60m) multilayered structure into a relatively small cylindrical volume. In order to increase overall efficiency, we employ radio frequency (RF) transparent PV over the antenna layer on one side of the sandwich and PV on the other to allow the antennas to point at the earth almost continually while in a geosynchronous equatorial orbit. We also have explored using optically transparent antennas over the PV layer which opens options for the types of antennas we can use. We summarize our progress to date and briefly discuss our impending on-orbit demonstration payload.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.
Phased arrays are multiple antenna systems capable of forming and steering beams electronically using constructive and destructive interference between sources. They are employed extensively in radar and communication systems but are typically rigid, bulky and heavy, which limits their use in compact or portable devices and systems. Here, we report a scalable phased array system that is both lightweight and flexible. The array architecture consists of a self-monitoring complementary metal–oxide–semiconductor-based integrated circuit, which is responsible for generating multiple independent phase- and amplitude-controlled signal channels, combined with flexible and collapsible radiating structures. The modular platform, which can be collapsed, rolled and folded, is capable of operating standalone or as a subarray in a larger-scale flexible phased array system. To illustrate the capabilities of the approach, we created a 4 × 4 flexible phased array tile operating at 9.4–10.4 GHz, with a low areal mass density of 0.1 g cm−2. We also created a flexible phased array prototype that is powered by photovoltaic cells and intended for use in a wireless space-based solar power transfer array.
This paper presents the analysis and design of a novel magnetic sensor. We study the underlying physics of inductance shift sensors as a special case of the broader family of magnetic energy deviation sensors. The result is a quantitative definition of performance metrics with all assumptions and approximations explicitly stated. This analysis is then used to design a modified ac Wheatstone bridge that uses two inductorpairs in a cross-coupled configuration, to half its size and double its transducer gain while maintaining a fully differential structure with a matched frequency response. A proof-of-concept sensor was fabricated with peripheral circuitry in a 65-nm bulk CMOS process to operate between 770 and 1450 MHz with an effective sensing area of 200 μm × 200 μm. The new bridge sensor is fully characterized at a frequency of 770 MHz and demonstrates a reliable and continuous detection of 4.5-μm iron-oxide magnetic beads over time periods longer than 30 min, appreciably longer than previously reported works.
Graph neural networks (GNNs) have shown broad applicability in a variety of domains. These domains, e.g., social networks and product recommendations, are fertile ground for malicious users and behavior. In this paper, we show that GNNs are vulnerable to the extremely limited (and thus quite realistic) scenarios of a single-node adversarial attack, where the perturbed node cannot be chosen by the attacker. That is, an attacker can force the GNN to classify any target node to a chosen label, by only slightly perturbing the features or the neighbors list of another single arbitrary node in the graph, even when not being able to select that specific attacker node. When the adversary is allowed to select the attacker node, these attacks are even more effective. We demonstrate empirically that our attack is effective across various common GNN types (e.g., GCN, GraphSAGE, GAT, GIN) and robustly optimized GNNs (e.g., Robust GCN, SM GCN, GAL, LAT-GCN), outperforming previous attacks across different real-world datasets both in a targeted and non-targeted attacks.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Chaim Baskin and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Moshe Guy and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@INPROCEEDINGS{nator2024coordination,
author={Nator, Hosen},
booktitle={Proceedings of the 2024 IEEE Information Theory Workshop (ITW)},
title={Coordination Capacity for Classical-Quantum States},
year={2024},
volume={},
number={},
pages={330-335},
doi={}}copy to clipboardDeep neural networks are known to be vulnerable to malicious perturbations. Current methods for improving adversarial robustness make use of either implicit or explicit regularization, with the latter is usually based on adversarial training. Randomized smoothing, the averaging of the classifier outputs over a random distribution centered in the sample, has been shown to guarantee a classifier’s performance subject to bounded perturbations of the input. In this work, we study the application of randomized smoothing to improve performance on unperturbed data and increase robustness to adversarial attacks. We propose to combine smoothing along with adversarial training and randomization approaches, and find that doing so significantly improves the resilience compared to the baseline. We examine our method’s performance on common white-box (FGSM, PGD) and black-box (transferable attack and NAttack) attacks on CIFAR-10 and CIFAR-100, and determine that for a low number of iterations, smoothing provides a significant performance boost that persists even for perturbations with a high attack norm, 𝜖.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@inproceedings{Abiri2022ALS,
title={A Lightweight Space-based Solar Power Generation and Transmission Satellite},
author={Behrooz Abiri and Manan Arya and Florian Bohn and Austin C. Fikes and Matan Gal-Katziri and Eleftherios Gdoutos and Ashish Goel and Pilar Espinet Gonz{\'a}lez and Michael D. Kelzenberg and Nicolas Lee and Michael A. Marshall and Tatiana A. Roy and Fabien Royer and Emily C. Warmann and Tatiana G. Vinogradova and Richard G. Madonna and Harry A. Atwater and Ali Hajimiri and S{\'e}rgio Roberto Matiello Pellegrino},
year={2022},
url={https://api.semanticscholar.org/CorpusID:249848189}
}copy to clipboardWe propose a novel design for a lightweight, high-performance space-based solar power array combined with power beaming capability for operation in geosynchronous orbit and transmission of power to Earth. We use a modular configuration of small, repeatable unit cells, called tiles, that each individually perform power collection, conversion, and transmission. Sunlight is collected via lightweight parabolic concentrators and converted to DC electric power with high efficiency III-V photovoltaics. Several CMOS integrated circuits within each tile generates and controls the phase of multiple independently-controlled microwave sources using the DC power. These sources are coupled to multiple radiating antennas which act as elements of a large phased array to beam the RF power to Earth. The power is sent to Earth at a frequency chosen in the range of 1-10 GHz and collected with ground-based rectennas at a local intensity no larger than ambient sunlight. We achieve significantly reduced mass compared to previous designs by taking advantage of solar concentration, current CMOS integrated circuit technology, and ultralight structural elements. Of note, the resulting satellite has no movable parts once it is fully deployed and all beam steering is done electronically. Our design is safe, scalable, and able to be deployed and tested with progressively larger configurations starting with a single unit cell that could fit on a cube satellite. The design reported on here has an areal mass density of 160 g/m2 and an end-to-end efficiency of 7-14%. We believe this is a significant step forward to the realization of space-based solar power, a concept once of science fiction.
@article{
kimhi2024semisupervised,
title={Semi-Supervised Semantic Segmentation via Marginal Contextual Information},
author={Moshe Kimhi and Shai Kimhi and Evgenii Zheltonozhskii and Or Litany and Moshe Guy},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=i5yKW1pmjW},
note={}
}copy to clipboardWe present a novel confidence refinement scheme that enhances pseudo-labels in semi-supervised semantic segmentation. Unlike existing methods, which filter pixels with low-confidence predictions in isolation, our approach leverages the spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo-labels collectively. With this contextual information, our method, named S4MC, increases the amount of unlabeled data used during training while maintaining the quality of the pseudo-labels, all with negligible computational overhead. Through extensive experiments on standard benchmarks, we demonstrate that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution for reducing the cost of acquiring dense annotations. For example, S4MC achieves a 1.39 mIoU improvement over the prior art on PASCAL VOC 12 with 366 annotated images.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Moshe Guy and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.
Phased arrays are multiple antenna systems capable of forming and steering beams electronically using constructive and destructive interference between sources. They are employed extensively in radar and communication systems but are typically rigid, bulky and heavy, which limits their use in compact or portable devices and systems. Here, we report a scalable phased array system that is both lightweight and flexible. The array architecture consists of a self-monitoring complementary metal–oxide–semiconductor-based integrated circuit, which is responsible for generating multiple independent phase- and amplitude-controlled signal channels, combined with flexible and collapsible radiating structures. The modular platform, which can be collapsed, rolled and folded, is capable of operating standalone or as a subarray in a larger-scale flexible phased array system. To illustrate the capabilities of the approach, we created a 4 × 4 flexible phased array tile operating at 9.4–10.4 GHz, with a low areal mass density of 0.1 g cm−2. We also created a flexible phased array prototype that is powered by photovoltaic cells and intended for use in a wireless space-based solar power transfer array.
Graph neural networks (GNNs) have shown broad applicability in a variety of domains. These domains, e.g., social networks and product recommendations, are fertile ground for malicious users and behavior. In this paper, we show that GNNs are vulnerable to the extremely limited (and thus quite realistic) scenarios of a single-node adversarial attack, where the perturbed node cannot be chosen by the attacker. That is, an attacker can force the GNN to classify any target node to a chosen label, by only slightly perturbing the features or the neighbors list of another single arbitrary node in the graph, even when not being able to select that specific attacker node. When the adversary is allowed to select the attacker node, these attacks are even more effective. We demonstrate empirically that our attack is effective across various common GNN types (e.g., GCN, GraphSAGE, GAT, GIN) and robustly optimized GNNs (e.g., Robust GCN, SM GCN, GAL, LAT-GCN), outperforming previous attacks across different real-world datasets both in a targeted and non-targeted attacks.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Chaim Baskin and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Chaim Baskin and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Moshe Guy and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardTest-Time Adaptation methods improve domain shift robustness of deep neural networks. We explore the adaptation of segmentation models to a single unlabelled image with no other data available at test time. This allows individual sample performance analysis while excluding orthogonal factors such as weight restart strategies. We propose two new segmentation ac{tta} methods and compare them to established baselines and recent state-of-the-art. The methods are first validated on synthetic domain shifts and then tested on real-world datasets. The analysis highlights that simple modifications such as the choice of the loss function can greatly improve the performance of standard baselines and that different methods and hyper-parameters are optimal for different kinds of domain shift, hindering the development of fully general methods applicable in situations where no prior knowledge about the domain shift is assumed.
@article{
kimhi2024semisupervised,
title={Semi-Supervised Semantic Segmentation via Marginal Contextual Information},
author={Moshe Kimhi and Shai Kimhi and Evgenii Zheltonozhskii and Or Litany and Moshe Guy},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=i5yKW1pmjW},
note={}
}copy to clipboardWe present a novel confidence refinement scheme that enhances pseudo-labels in semi-supervised semantic segmentation. Unlike existing methods, which filter pixels with low-confidence predictions in isolation, our approach leverages the spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo-labels collectively. With this contextual information, our method, named S4MC, increases the amount of unlabeled data used during training while maintaining the quality of the pseudo-labels, all with negligible computational overhead. Through extensive experiments on standard benchmarks, we demonstrate that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution for reducing the cost of acquiring dense annotations. For example, S4MC achieves a 1.39 mIoU improvement over the prior art on PASCAL VOC 12 with 366 annotated images.
Graph neural networks (GNNs) have shown broad applicability in a variety of domains. These domains, e.g., social networks and product recommendations, are fertile ground for malicious users and behavior. In this paper, we show that GNNs are vulnerable to the extremely limited (and thus quite realistic) scenarios of a single-node adversarial attack, where the perturbed node cannot be chosen by the attacker. That is, an attacker can force the GNN to classify any target node to a chosen label, by only slightly perturbing the features or the neighbors list of another single arbitrary node in the graph, even when not being able to select that specific attacker node. When the adversary is allowed to select the attacker node, these attacks are even more effective. We demonstrate empirically that our attack is effective across various common GNN types (e.g., GCN, GraphSAGE, GAT, GIN) and robustly optimized GNNs (e.g., Robust GCN, SM GCN, GAL, LAT-GCN), outperforming previous attacks across different real-world datasets both in a targeted and non-targeted attacks.
@article{
janouskova2024single,
title={Single Image Test-Time Adaptation for Segmentation},
author={Klara Janouskova and Tamir Shor and Chaim Baskin and Jiri Matas},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=68LsWm2GuD},
note={}
}copy to clipboardConvolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method does not require fine-tuning the network weights and halves the data transfer volumes to the main memory by compressing feature maps, which are highly correlated, with variable length coding. Our method outperform previous approach in term of the number of bits per value with minor accuracy degradation on ResNet-34 and MobileNetV2. We analyze the performance of our approach on a variety of CNN architectures and demonstrate that FPGA implementation of ResNet-18 with our approach results in a reduction of around 40% in the memory energy footprint, compared to quantized network, with negligible impact on accuracy. When allowing accuracy degradation of up to 2%, the reduction of 60% is achieved. A reference implementation accompanies the paper.